PostgreSQL streaming read replications
Amazon RDS users can create up to five DB instances using a snapshot of the source PostgreSQL DB instance.
It uses the native streaming replication available on the PostgreSQL engine to asynchronously update the read replicas whenever there is a change to the source DB instance.
Amazon RDS writes all changes to the source DB instance, including data definition language (DDL).
Replicas are read only and used to handle the read request workload.
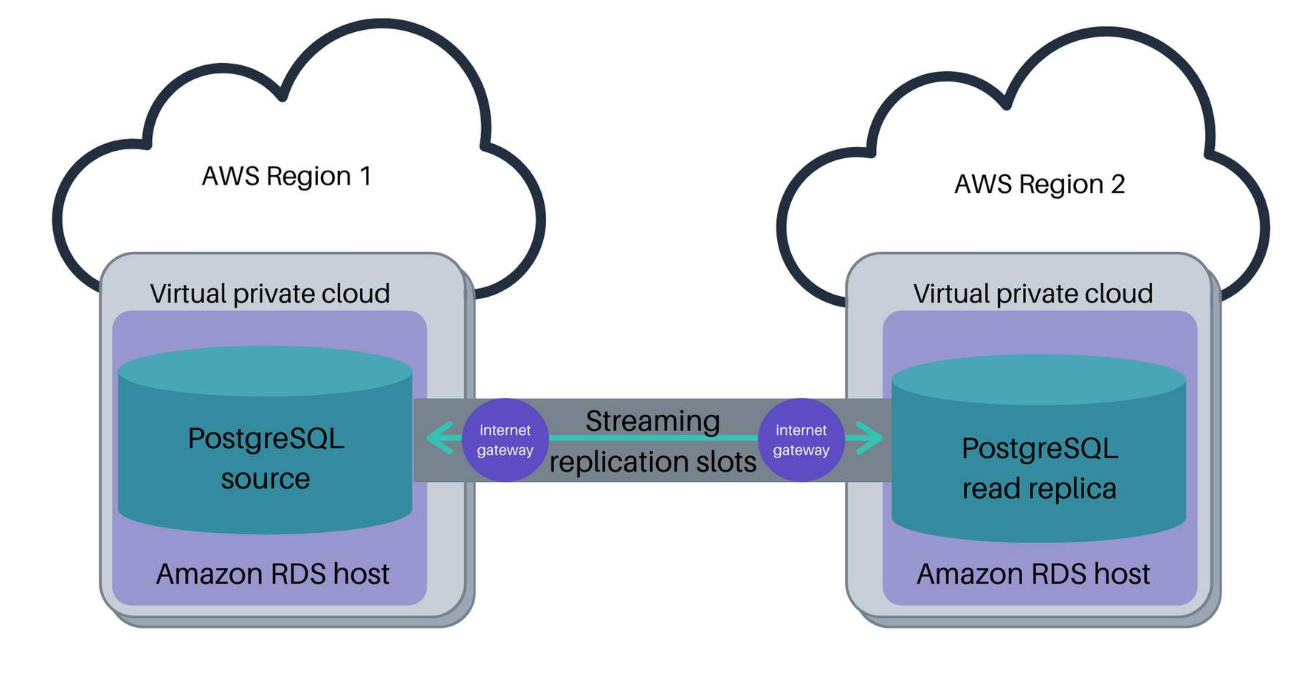
The following diagram shows how Amazon RDS PostgreSQL performs replication between a source and a replica in the same AWS Region.
In this example, Amazon RDS is hosting the source and read replica. The user can then stream replication directly between the source and read replica. The user has stored archived Write Ahead Logs (WALs) using an Amazon Simple Storage Service (Amazon S3)
Then, if needed, the Amazon S3 backup can restore WALs in the read replica

Tuning Amazon RDS replication
You can tune the Amazon RDS PostgreSQL replication process to control how the replication behaves.
This tuning can affect how far behind a replica is allowed to get before canceling newly submitted queries.
For more information about tuning, see the Amazon RDS User Guide.
Select each + to learn more about Amazon RDS replication tuning commands
wal_keep_segments
–
This specifies the number of WAL file segments to keep on the primary instance.
Amazon RDS PostgreSQL archives segments to Amazon S3 and must download segments needed to sync a replica that has fallen behind.
hot_standby_feedback
–
This parameter is set on each replica. It controls whether the replica sends feedback to the primary database about queries running on the replica.
This prevents the vacuum from removing tuples on the primary that are still needed to satisfy long-running queries on a replica.
max_standby_archive_delay
–
This command and the max_standby_streaming_delay command configure how long a replica will pause WAL replay to complete queries running on the replica.
If a query causes the delay to exceed the maximum, the query is canceled so that WAL replay can resume.
Aurora read replicas
Aurora further increases your horizontal scaling capability through the use of read replicas.
Aurora uses a solid state drive (SSD) virtualized storage layer. The SSD facilitates the efficient handling of database workloads.
Aurora read replicas share the same underlying storage as the primary source instance.
This helps reduce costs and eliminates the need to copy data to the read replicas.
Horizontal scaling of Aurora read replicas is extremely fast, no matter how much you scale the size of the database.
This is because there is no need to copy the data to the new read replica.
For more information about replication with Aurora, see Replication with Amazon Aurora.
To learn more about how read replicas work in Aurora, select each numerical button in order.


Logical and physical replication differences
Logical and physical replication differences
Logical replication differs from physical replication in several ways:
- Users can replicate changes from an earlier version of PostgreSQL to a later version.
- Users can choose a subset of tables to replicate.
- Data can flow in multiple directions.
- DDL is not replicated.
- Logical replication requires manual configuration.
Enabling logical replication for Amazon RDS
Enabling logical replication for Amazon RDS
Logical replication works for replicating changes from PostgreSQL instances running on premises or self managed on Amazon Elastic Compute Cloud (Amazon EC2). It also works for upgrades in PostgreSQL versions.
Additional CPU overhead can affect performance. This additional overhead comes from converting changes made in the source database to a set of logical SQL commands run on a replica.
To review how to enable logical replication in Amazon RDS, select Start.
Amazon RDS: Enabling logical replication
Select Start to see how to enable logical replication for an Amazon RDS for PostgreSQL DB instance as a publisher.
Step 1: Required roles
The AWS user account requires the rds_superuser role to perform logical replication for the database on Amazon RDS.
The user account also requires the rds_replication role to grant permissions to manage logical slots and stream data using logical slots.
Step 2: Set parameters
Set the rds.logical_replication static parameter to 1.
Step 3: Set connection security
Modify the inbound rules of the security group for the publisher instance (production) to allow the subscriber instance (replica) to connect.
This is usually done by including the Internet Protocol (IP) address of the subscriber in the security group.
Step 4: Reboot the DB instance
Reboot the DB instance for the changes to the static parameter rds.logical_replication to take effect.
| Parameter | Minimum | Recommended |
|---|---|---|
| max_replication_slots | 2 | 4 |
| max_logical_replication_workers | 2 | 4 |
| max_worker_processes | 2 | 12 |
Managing Database Connections


Most application servers and programming language environments provide a client-side connection pool for the application to reuse a group of existing connections (a pool) rather than creating a new connection for each user request.

For example, Java developers use open-source connection pool libraries such as Apache Commons DBCP, HikariCP, or C3PO. Ruby on Rails and .NET Npgsql developers use a connection pool built into their respective database drivers.
Using these connection pools, each application server can access database resources and process user queries more quickly and efficiently.

As you scale your application, managing the total number of connections coming from multiple application servers becomes important.
Each application server might have a small pool of 10 database connections. However, as the application tier automatically scales from 10 to 100 to 1,000 application servers, the number of database connections grows exponentially with them. Pooling and reusing connections reduces the total database connections created.
Connection Pools 4

Each open connection in PostgreSQL, whether idle or active, consumes memory (about 10 MB), which reduces memory available for the database engine or file system caching.
You can control the number of incoming connections allowed to your database with the PostgreSQL parameter max_connections.

Ensure that the maximum connections configured on the database server and the working memory configured for each connection do not exceed available free memory. In a worst-case scenario, a database restart will occur. This restart happens if the database engine allows more connections to be opened than the available memory can accommodate.
For more information about connection management in PostgreSQL, see the PostgreSQL Wiki.
Database proxies
Add a database proxy to your database architecture to increase speed and reduce connection overhead.
Proxies provide a separate layer of database connection pools. This separate layer can reuse existing or duplicate connections. This proxy can also direct writes to the primary while offloading read requests to the read replicas.
Proxies are useful when you have many application servers or use a serverless application architecture to create a connection pool shared by all your applications.
Configuring and managing your connection pool using a client-side library, such as a Java, Python, or Ruby connection library, is appropriate when your application is small. However, as your application grows, or if you move toward a serverless application architecture, you should introduce a database proxy to manage that pool of connections in a shared layer in between your application and the database. Those connections can then be shared across multiple application servers and be reused as your application gets larger and the number of application servers continues to grow. Amazon RDS Proxy is a fully managed service that provides a connection pooling proxy layer with extensive functionality. In addition, there are two open-source PostgreSQL proxy servers—pgBouncer and pgPool 2—on Amazon EC2 that you can configure and manage on your own to support similar types of connection pooling functionality.
Amazon RDS Proxy
Amazon RDS Proxy is a highly manageable database proxy. It automatically connects to a new database instance while preserving application connections. When failovers occur, Amazon RDS Proxy routes requests directly to the new database instance. This reduces failover duration for Aurora and Amazon RDS databases by up to 66 percent.
Amazon RDS Proxy helps you manage elements such as database credentials, authentication, and access through integration with AWS Secrets Manager and AWS Identity and Access Management (IAM).

PostgreSQL proxy servers
PgBouncer and Pgpool-II are open-source PostgreSQL proxy servers that you can use to manage connections and traffic for your database on Amazon EC2.
One way to help increase efficiency with a database proxy is to use it to direct write queries to the primary DB instance and read-only queries to one or more read replicas.
PgBouncer
PgBouncer is an open-source connection pooling utility used in PostgreSQL to maintain a cached pool of connections. Applications interact with PostgreSQL through these connections.
A few features of PgBouncer include:
- Provides a lightweight connection pooler
- Queues requests
- Helps improve availability
This graphic shows how PgBouncer works to pool connections.

Pgpool-II
Pgpool-II
Pgpool-II is middleware that works between PostgreSQL servers and a PostgreSQL database client. For more information, see the Pgpool-II documentation.

This diagram illustrates how Pgpool-II works as a proxy to direct application traffic.
No comments:
Post a Comment